Note
Go to the end to download the full example code.
Alignment methods benchmark (template-based ROI case)¶
In this tutorial, we compare various methods of alignment on a group-based alignment problem for Individual Brain Charting subjects. For each subject, we have a lot of functional information in the form of several task-based contrast per subject. We will just work here on a ROI.
We mostly rely on python common packages and on nilearn to handle functional data in a clean fashion.
To run this example, you must launch IPython via ipython --matplotlib in
a terminal, or use jupyter-notebook.
Retrieve the data¶
In this example we use the IBC dataset, which include a large number of different contrasts maps for 12 subjects.
The contrasts come from tasks in the Archi and HCP fMRI batteries, designed to probe a range of cognitive functions, including:
Motor control: finger, foot, and tongue movements
Social cognition: interpreting short films and stories
Spatial orientation: judging orientation and hand-side
Numerical reasoning: reading and listening to math problems
Emotion processing: judging facial expressions
Reward processing: responding to gains and losses
Working memory: maintaining sequences of faces and objects
Object categorization: matching and comparing visual stimuli
# We download the images for subjects sub-01 and sub-02.
# ``files`` is the list of paths for each subjects.
# ``df`` is a dataframe with metadata about each of them.
# ``mask`` is the common mask for IBC subjects.
from fmralign.fetch_example_data import fetch_ibc_subjects_contrasts
sub_ids = ["sub-01", "sub-02", "sub-04"]
files, df, mask = fetch_ibc_subjects_contrasts(sub_ids)
[get_dataset_dir] Dataset found in /home/runner/nilearn_data/ibc
Extract a mask for the visual cortex from Yeo Atlas¶
First, we fetch and plot the complete atlas
from nilearn import datasets, plotting
from nilearn.image import concat_imgs, load_img, new_img_like, resample_to_img
atlas_yeo_2011 = datasets.fetch_atlas_yeo_2011()
atlas = load_img(atlas_yeo_2011.maps)
# Select visual cortex, create a mask and resample it to the right resolution
mask_visual = new_img_like(atlas, atlas.get_fdata() == 1)
resampled_mask_visual = resample_to_img(
mask_visual, mask, interpolation="nearest"
)
# Plot the mask we will use
plotting.plot_roi(
resampled_mask_visual,
title="Visual regions mask extracted from atlas",
cut_coords=(8, -80, 9),
colorbar=False,
cmap="Paired",
)
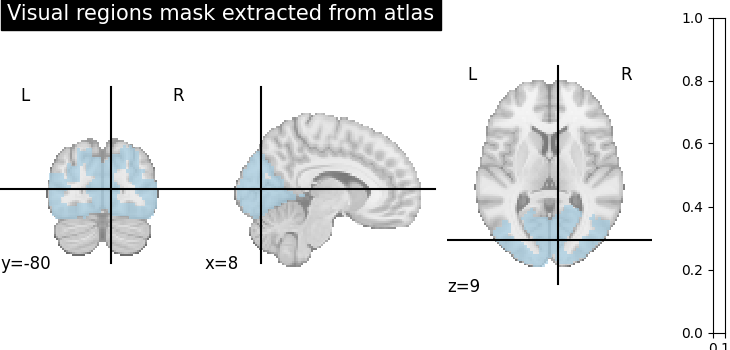
[fetch_atlas_yeo_2011] Dataset found in /home/runner/nilearn_data/yeo_2011
<nilearn.plotting.displays._slicers.OrthoSlicer object at 0x7f43dd94e9f0>
Define a masker¶
We define a nilearn masker that will be used to handle relevant data. For more information, consult Nilearn’s documentation on masker objects.
from nilearn.maskers import NiftiMasker
roi_masker = NiftiMasker(mask_img=resampled_mask_visual).fit()
Prepare the data¶
For each subject, for each task and conditions, our dataset contains two independent acquisitions, similar except for one acquisition parameter, the encoding phase used that was either Antero-Posterior (AP) or Postero-Anterior (PA). Although this induces small differences in the final data, we will take advantage of these pseudo-duplicates to define training and test samples.
# The training set:
# * source_train: AP acquisitions from source subjects (sub-01, sub-02).
# * target_train: AP acquisitions from the target subject (sub-04).
#
source_subjects = [sub for sub in sub_ids if sub != "sub-04"]
source_train_imgs = [
concat_imgs(df[(df.subject == sub) & (df.acquisition == "ap")].path.values)
for sub in source_subjects
]
target_train_img = concat_imgs(
df[(df.subject == "sub-04") & (df.acquisition == "ap")].path.values
)
# The testing set:
# * source_test: PA acquisitions from source subjects (sub-01, sub-02).
# * target test: PA acquisitions from the target subject (sub-04).
#
source_test_imgs = [
concat_imgs(df[(df.subject == sub) & (df.acquisition == "pa")].path.values)
for sub in source_subjects
]
target_test_img = concat_imgs(
df[(df.subject == "sub-04") & (df.acquisition == "pa")].path.values
)
Choose the number of regions for local alignment¶
First, as we will proceed to local alignment we choose a suitable number of regions so that each of them is approximately 100 voxels wide. Then our estimator will first make a functional clustering of voxels based on train data to divide them into meaningful regions.
The chosen region of interest contains 6631.0 voxels
We will cluster them in 66 regions
Extract the parcels labels¶
We will use intra-parcel alignments, fmralign provides a simple utility
to extract the labels of associated to each voxel:
get_labels.
We then organize the data in dictionaries of pairs of subjects names and data.
from fmralign.embeddings.parcellation import get_labels
labels = get_labels(source_train_imgs, roi_masker, n_pieces)
dict_source_train = dict(
zip(
source_subjects,
[roi_masker.transform(img) for img in source_train_imgs],
)
)
dict_source_test = dict(
zip(
source_subjects,
[roi_masker.transform(img) for img in source_test_imgs],
)
)
target_train = roi_masker.transform(target_train_img)
target_test = roi_masker.transform(target_test_img)
/home/runner/work/fmralign/fmralign/fmralign/embeddings/parcellation.py:114: UserWarning: Converting masker to multi-masker for compatibility with Nilearn Parcellations class. This conversion does not affect the original masker. See https://github.com/nilearn/nilearn/issues/5926 for more details.
warnings.warn(
/home/runner/work/fmralign/fmralign/fmralign/embeddings/parcellation.py:134: UserWarning: Overriding provided-default estimator parameters with provided masker parameters :
Parameter mask_strategy :
Masker parameter background - overriding estimator parameter epi
Parameter smoothing_fwhm :
Masker parameter None - overriding estimator parameter 4.0
parcellation.fit(images_to_parcel)
/home/runner/work/fmralign/fmralign/.venv/lib/python3.12/site-packages/sklearn/cluster/_agglomerative.py:324: UserWarning: the number of connected components of the connectivity matrix is 11 > 1. Completing it to avoid stopping the tree early.
connectivity, n_connected_components = _fix_connectivity(
Define the estimators, fit them and do a prediction¶
On each region, we search for a transformation R that is either:
orthogonal, using
Procrustess.t. ||sc RX - Y ||^2 is minimized, where sc is a scaling factorthe
OptimalTransportplan, which yields the minimal transport cost while respecting the mass conservation constraints. Calculated with entropic regularization.the deterministic shared response model (
DetSRM), which computes a shared response space from different subjects, and then projects individual subject data into it.
Then for each method we define the estimator, fit it, predict the new image and plot its correlation with the real signal. We use the identity (euclidean averaging) as the baseline.
from fmralign import GroupAlignment
from fmralign.metrics import score_voxelwise
methods = ["identity", "procrustes", "ot", "SRM"]
# Prepare to store the results
titles, aligned_scores = [], []
for i, method in enumerate(methods):
# Fit the group estimator on the training data
group_estimator = GroupAlignment(method=method, labels=labels).fit(
dict_source_train
)
# Compute a mapping between the template and the new subject
# using `target_train` and make a prediction using the left-out-data
target_pred = group_estimator.predict_subject(
dict_source_test, target_train
)
# Derive correlation between prediction, test
method_error = score_voxelwise(target_test, target_pred, loss="corr")
# Store the results for plotting later
aligned_score_img = roi_masker.inverse_transform(method_error)
titles.append(f"Correlation of prediction after {method} alignment")
aligned_scores.append(aligned_score_img)
/home/runner/work/fmralign/fmralign/fmralign/metrics.py:55: ConstantInputWarning: An input array is constant; the correlation coefficient is not defined.
pearsonr(X_gt[:, vox], X_pred[:, vox])[
/home/runner/work/fmralign/fmralign/.venv/lib/python3.12/site-packages/ot/bregman/_sinkhorn.py:902: UserWarning: Sinkhorn did not converge. You might want to increase the number of iterations `numItermax` or the regularization parameter `reg`.
warnings.warn(
Plot the results¶
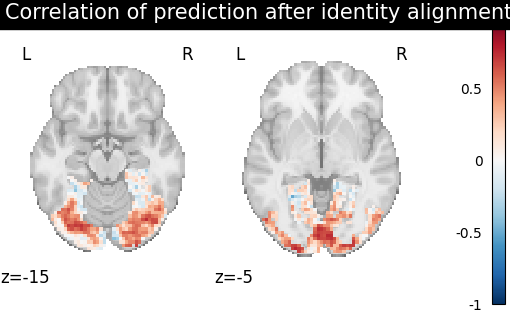
/home/runner/work/fmralign/fmralign/examples/plot_alignment_methods_benchmark.py:217: UserWarning: Non-finite values detected. These values will be replaced with zeros.
plotting.plot_stat_map(
Summary:¶
We compared GroupAlignment methods
(i.e., OptimalTransport,
Procrustes)
with DetSRM alignment on visual cortex activity.
You can see that DetSRM introduces more
smoothness in the transformation, resulting in slightly higher correlation values.
Total running time of the script: (0 minutes 49.073 seconds)