Note
This page is a reference documentation. It only explains the class signature, and not how to use it. Please refer to the user guide for the big picture.
fmralign.alignment.group_alignment.GroupAlignment¶
- class fmralign.alignment.group_alignment.GroupAlignment(method='identity', labels=None, n_jobs=1, verbose=0, n_iter=2, scale_template=False)[source]¶
Performs group-level alignment of various subject data.
This class aligns multiple subjects’ data either to a computed template or to a specific target subject’s data. It supports various alignment methods and can process data in parallel.
- Parameters:
- methodstr or a BaseAlignment instance, default=”identity”
The alignment method to use. It can be a string representing the method name or an instance of a class derived from BaseAlignment. Available methods include: [“identity”, “procrustes”, “ot”, “ridge”].
- labelsarray-like or None, default=None
Describes each voxel label’s in the case of non-overlapping parcels. If provided, local alignments can be performed in parallel. If None, global alignment is performed across all features.
- n_jobsint, default=1
Number of parallel jobs to run. -1 means using all processors.
- verboseint, default=0
Verbosity level. Higher values provide more detailed output.
- n_iterint, default=2
Number of iterations for the template alignment algorithm.
- scale_templatebool, default=False
Whether to scale the features during template learning. If True, features are rescaled to the updating Euclidean mean.
- Attributes:
- labels_array-like
Validated labels used during fitting.
- method_str
Validated alignment method used during fitting.
- fit_list
List of fitted alignment estimators, one per subject.
- templatearray-like or None
Computed template for template alignment. None for pairwise alignment.
Examples
>>> import numpy as np >>> from fmralign import GroupAlignment >>> n_voxels = 5
>>> # Template alignment >>> alignment_dict = { ... "sub-01": np.random.rand(10, n_voxels), ... "sub-02": np.random.rand(10, n_voxels), ... } >>> testing_dict = { ... "sub-01": np.random.rand(8, n_voxels), ... "sub-02": np.random.rand(8, n_voxels), ... } >>> aligner = GroupAlignment(method="procrustes", n_iter=3) >>> aligner.fit(alignment_dict, y="template") >>> aligned_data = aligner.transform(testing_dict)
>>> # Pairwise alignment to target >>> target_data = np.random.rand(10, n_voxels) >>> aligner = GroupAlignment(method="procrustes") >>> aligner.fit(alignment_dict, y=target_data) >>> aligned_data = aligner.transform(testing_dict)
- __init__(method='identity', labels=None, n_jobs=1, verbose=0, n_iter=2, scale_template=False)[source]¶
- fit(X, y='template')[source]¶
Fit the group alignment model to the data.
- Parameters:
- Xdict of array-like
Dictionary where keys are subject identifiers and values are arrays of subject data. Each array should have the same number of samples and features.
- ystr or array-like, default=”template”
Alignment target, which determines the alignment strategy:
“template”: Compute a single template from all subjects and align each subject to this shared template.
“leave_one_subject_out”: Perform Leave-One-Subject-Out alignment. For each subject, compute a template from all other subjects, then align that subject to its corresponding template. This process repeats for every subject.
array-like: Align all subjects to the provided target data array.
- get_metadata_routing()¶
Get metadata routing of this object.
Please check User Guide on how the routing mechanism works.
- Returns:
- routingMetadataRequest
A
MetadataRequestencapsulating routing information.
- get_params(deep=True)¶
Get parameters for this estimator.
- Parameters:
- deepbool, default=True
If True, will return the parameters for this estimator and contained subobjects that are estimators.
- Returns:
- paramsdict
Parameter names mapped to their values.
- predict_subject(X_test, Y_new)[source]¶
Fit a new subject to the template and predict test data.
- Parameters:
- X_testdict of array-like
Dictionary where keys are subject identifiers and values are array of subject held-out data used to make a prediction on the template.
- Y_newarray-like
Data used to fit the new subject to a pre-existing template.
- Returns:
- array-like
Predicted response on the new subject using the response computed on the template.
- set_output(*, transform=None)¶
Set output container.
Refer to the user guide for more details and Introducing the set_output API for an example on how to use the API.
- Parameters:
- transform{“default”, “pandas”, “polars”}, default=None
Configure output of transform and fit_transform.
“default”: Default output format of a transformer
“pandas”: DataFrame output
“polars”: Polars output
None: Transform configuration is unchanged
Added in version 1.4: “polars” option was added.
- Returns:
- selfestimator instance
Estimator instance.
- set_params(**params)¶
Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as
Pipeline). The latter have parameters of the form<component>__<parameter>so that it’s possible to update each component of a nested object.- Parameters:
- **paramsdict
Estimator parameters.
- Returns:
- selfestimator instance
Estimator instance.
- transform(X)[source]¶
Transform the input arrays using the fitted model.
- Parameters:
- Xdict of array-like
Dictionary where keys are subject identifiers and values are array of subject data. Each array should have the same number of samples and features.
- Returns:
- dict of array-like
Dictionary with transformed subject data.
Examples using fmralign.alignment.group_alignment.GroupAlignment¶
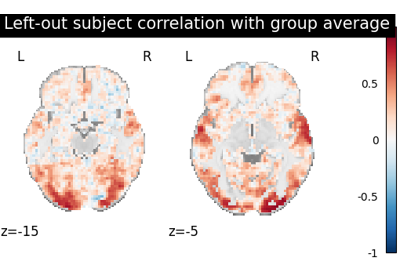
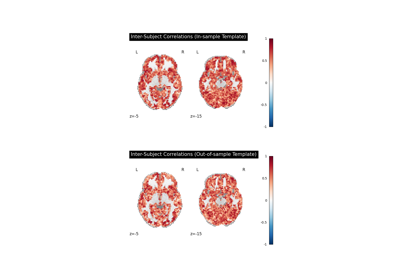
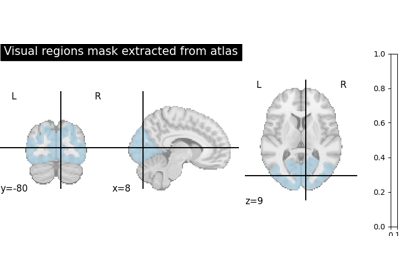
Alignment methods benchmark (template-based ROI case)